Vocabulary and English for Specific Purposes Research - Averil Coxhead 2018
Background and issues in word list research for ESP
The role and value of word list research for ESP
In vocabulary research, corpus linguistics studies use word lists for various reasons, including identifying, classifying and quantifying the amount or proportion of technical vocabulary in texts. Ways to identify specialised vocabulary were explored in Chapter 2. This kind of research tells us more about the nature and size of technical vocabulary in particular professional and academic areas, helps us track technical vocabulary change over time, and enables the assessment of the vocabulary load of texts. This chapter focuses on such uses of word lists for vocabulary in ESP.
A particular use of word lists is to estimate the coverage of a list over a text or corpus (see Nation, 2016; Nation, 2006; Coxhead, 2000). The purpose of these estimates is to find out how many words are needed to understand a text. Laufer (1989) suggests that 95% coverage is needed for comprehension but later estimates such as Nation (2006) and Hu and Nation (2000; see also Schmitt, Jiang & Grabe, 2011) suggest 98% is needed for written texts. Note that 98% coverage reported in Nation’s (2006) study equates to 8,000 word families (see the section on units of counting that follows for more on word families). In a study of spoken texts, van Zeeland and Schmitt (2013) find 95% coverage is sufficient for listening comprehension. Hsu (2014) is an example of an ESP analysis (using Engineering textbooks) which uses coverage figures to develop a word list for a particular group of learners in Taiwan. For a discussion of coverage and suggestions for replication research in this area, see Schmitt, Cobb, Horst and Schmitt (2017).
Word list research has also been driven by the needs of particular groups of language learners and to help set learning goals (Nation, 2016). While early word list development was based perhaps on a mix of judgement and counting words by hand in texts, computer-based approaches have recently made the process quicker. It is now also considerably easier to make word lists, whether they are motivated by the needs of particular learners or not. This, in turn, means that critical assessments are needed of both existing and newly developed lists to determine their usefulness and validity.
In pedagogically oriented word list development, the proficiency of the students, the subject area, their needs and the context for their studies all affect how the lists are made. Technical vocabulary would generally be expected to be limited in range to its specialised subject area or discipline and to be well known and regularly used by professionals in that field. People outside the specialised field might have a limited knowledge of that vocabulary, or might have never heard or come across these technical items at all. In some cases, the meaning of a word might be vaguely known by laypeople, but a specialist would be expected to know much more precise information about its meaning, use and nuances. Take the example of file from Carpentry (a file is used in woodwork or metalwork, for example, to smooth a surface) and consider what a layperson might know about that word (where file commonly means to organise paper into folders in an office) in comparison to a carpenter.
A fundamental issue in word list development is whether there is a common core of vocabulary which is shared by all language learners or whether all vocabulary is specialised (Basturkmen, 2006; Coxhead, 2013). This issue is important because it affects the starting point of the development of a word list for ESP. A common core approach attempts to take into account prior or existing knowledge of high frequency vocabulary by learners, whereas the second approach does not make that assumption. Also, a common core approach assumes different disciplines share a common core of academic language, which means an EAP teacher should focus on those items first, leaving the discipline-specific vocabulary to be learnt outside the EAP class in the learner’s discipline. The teaching context plays a major part in the common core versus specialised debate. In wide-angled contexts where English for General Academic Purposes (EGAP) has been selected, for example in English as a second language contexts such as Aotearoa/New Zealand, Australia, Canada, Britain and the USA, the teacher is likely to have a heterogeneous group of students, and cannot tailor what they do to one discipline. But in more specific models, where the learners are more homogeneous, a more specific approach makes sense (see Basturkmen (2010) for more on wide to narrow angled approaches to ESP).
An example of a common core approach is Coxhead’s AWL (2000), which used the first 2,000 word families of West’s (1953) General Service List of English Words (GSL) as a principled high frequency word list. To take into account the existing knowledge of learners studying to enter university or at university in English-medium institutions, items selected for the AWL had to occur outside of West’s GSL. A disadvantage of this approach is that any weaknesses or decisions made in the development of West’s GSL affect the AWL (see for example, Coxhead, 2000; Hyland & Tse, 2007; Nation & Webb, 2011; Gardner & Davies, 2014). One principle which West (1953) employed is ’coverage’, which meant that he selected items based on their overall utility for language learners. That is, if one item, such as ’work’ provided coverage of a concept, then he selected that item in favour of other similar items (such as ’job’). In Coxhead’s (2000) study, ’job’ met the principles for selection for the AWL and is therefore included in the list. Other examples are ’end’ (GSL) and ’final’ (AWL). This principle, therefore, had an effect on the AWL and on other lists based on the GSL/AWL studies.
A specialised approach to making word lists would begin with no existing word list to represent existing knowledge. A clear advantage of this approach is that it fits well with particular groups of learners, in terms of their language learning needs. An example of this approach is Ward’s (2009) Engineering word list for lower proficiency university students in Thailand. Ward’s word list contains 299 word types (that is, individual words rather than word families) and covers 16.4% of a corpus of Engineering textbooks. It is important to note that of the 299 word types, 188 are also in the first 1,000 word families in West’s (1953) GSL, 28 are in the second 1,000 of West’s GSL and 78 also occur in the AWL. The top ten words from Ward’s list are system, shown, equation, example, value, design, used, section, flow and given (Ward, 2009).
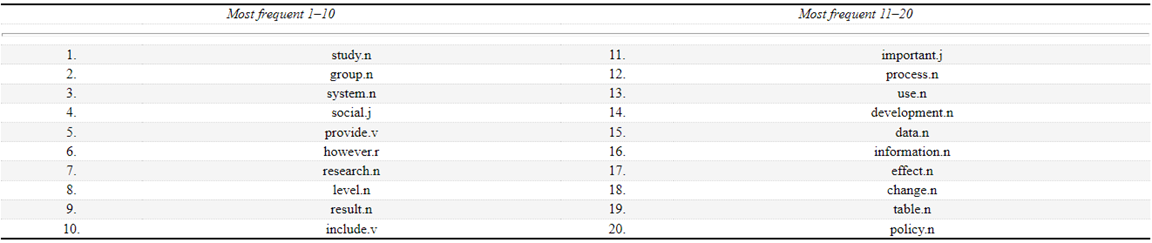
Another example of a specialised approach, but this time for general academic English, is Gardner and Davies’ (2014) AVL. This list contains around 3,000 lemmas. A lemma contains a baseword (for example, develop) and the inflections of the same part of speech (develops, developed, developing). Table 3.1 contains the top-20 lemmas in the AVL, including their part of speech. Gardner and Davies changed the lemma-based list into word families so that they could compare the AVL with other word lists such as Coxhead’s (2000) AWL. The lemma and family lists are downloadable at www.academicwords.info.
Note that the items listed in Table 3.1 from the AVL might seem to also be high frequency items in general English. Nation (2016) points out that the selection criteria for the AVL resulted in high frequency lemmas such as between, however and group being included, noting that these words ’seem to be only marginally academic’ (p. 150). In a recent study on the AVL, Durrant (2016) investigated the AVL coverage over the BAWE corpus and found that the average coverage of the AVL was 34% over each text in the BAWE. This finding suggests that the AVL is a very useful resource for researchers, teachers and learners and in EAP.
Table 3.1 The top 20 lemmas in the AVL (Gardner & Davies, 2014, p. 317)
Flowerdew (2014, p. 27) comments on the core versus specificity debate by saying, ’perhaps the conclusion that can best be drawn is that… different studies generate different results on account of the varied composition of the corpora and different software used.’ The short discussion earlier on core versus specific word lists certainly bears out Flowerdew’s observation.