Vocabulary and English for Specific Purposes Research - Averil Coxhead 2018
Developing word lists for ESP using corpora
The role and value of word list research for ESP
In this section, the kinds of research-based decisions which have to be made when developing a word list using corpora are discussed, drawing on examples from Coxhead (2000) on the development of the AWL and several other word lists. As Chapter 2 shows, corpus-based studies create opportunities for large-scale analyses of words and multi-word units in a range of texts, including spoken, written and multi-modal texts. Corpus studies should allow for replication and current research tools can accommodate multi-millions of words. While the computer-based analyses can be quite quick, corpus studies still require principled decision making by humans (Byrd & Coxhead, 2010), and this process can be very time consuming. Some of the methodological considerations and decisions for corpus building in the development of word lists include the size and context of the corpus, the kinds of texts and representativeness, the balance of the corpus and length of texts and how many corpora are required. See also Nation and Webb (2011) and Nation (2016) for an outline of general principles and guidelines on how to develop word lists.
One decision on developing a word list is whether the corpus will be written or spoken or both written or spoken. There are often practical reasons for choosing written texts over spoken, and we can see that there are many more word lists in EAP and ESP which are based on written, not spoken, texts. Dang, Coxhead and Webb (in press) developed a spoken academic word list to address this issue. Spoken texts are considerably more difficult to obtain, because they involve more steps in gathering and checking the data. Compare, for example, the effort and funding required to record a corpus of specialised English in first-year university Law lectures compared to locating and downloading or buying online texts related to the topics of the first-year Law class. The written documents are far easier to acquire than the spoken documents. Furthermore, the size and scale of the written documents, such as whole textbooks as opposed to possibly quite short interactions on building sites, are likely to far outweigh the number of words in spoken texts. Ways to deal with this problem include ensuring all documents contain the same number of running words, using a programme which automatically cuts off texts at a specific number of running words, adopting a norming where researchers adjust the raw frequency of words in texts (the formula for adjustment depends on the basis for norming, for example, 1,000 words or 1,000,000 words) (see Biber, Conrad & Reppen, 1998), or employing ratios. An important concept concerning the distribution of vocabulary in texts is Zipf’s law (1935), which states that the frequency of words in a text multiplied by its rank in a frequency-based list results in a constant figure. This means that high frequency words which have a high rank in a word list occur frequently, and items with low frequency have a low rank, but if we multiply the rank of these words by their frequency, the rank by frequency number will be roughly the same. Approximately half of the different words in a text occur only once, which makes norming difficult. See Nation (2016, pp. 3—5) for more explanation and examples in course design for Zipf’s law.
An example of such decision making that informs and affects the methodology of a corpus study can be seen in a study by Coxhead and Hirsh (2007). They wanted to find out whether there was a group of lexical items outside West’s GSL (1953) and Coxhead’s (2000) AWL which occurred with wide range and reasonable frequency across university-level Science texts. One of the early steps was the development of the corpus for the study. Coxhead and Hirsh used the seven existing Science subject corpora from Coxhead’s (2000) written corpus of academic texts. They added seven more subjects to increase the size and scope of the corpus.
The additions to the Science corpus were made to cover a wider range of subject areas at the first-year university level. When developing the AWL corpus, Coxhead (2000) did not collect Engineering and Medicine texts because those subjects were not taught at the first-year level at the university where she collected her corpus at that time. In 2007, Coxhead and Hirsh (2007) expanded the corpus to include those two subjects, and the five others, to represent the wider scope of first-year subjects offered as majors at Massey University, New Zealand (where Coxhead was then working) and the University of Sydney, Australia (where Hirsh is based). Studies at second or third year or postgraduate levels were not included because the purpose of the study was to develop a word list to support learners preparing to study at a first-year level at university in an English-medium university. See Table 3.2 for the list of subject areas and the number of running words in each subject in the corpus. Note that the sub-corpora are all roughly similar in size. An asterisk (*) denotes the seven new subject areas developed for the Science-specific word list.
Table 3.2 Fourteen subject areas of the written Science corpus (Coxhead & Hirsh,2007, p. 70)
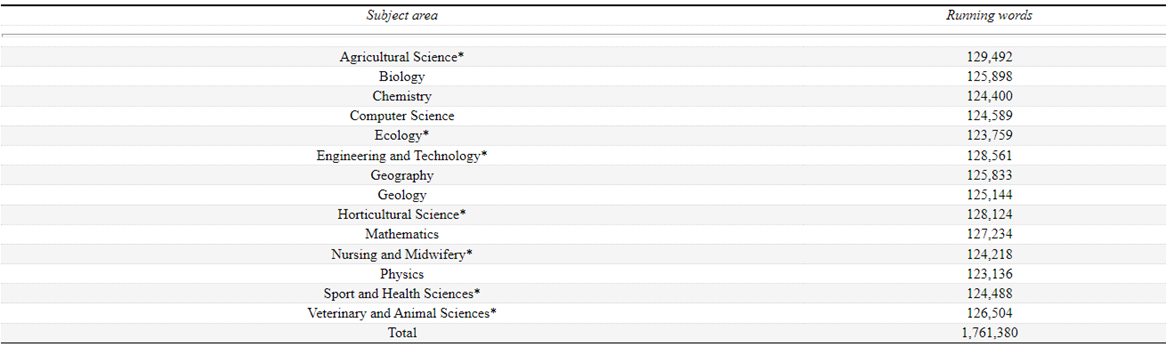
Coxhead and Hirsh (2007) made a pragmatic decision to focus on developing a smaller, balanced, wide-ranging corpus, in favour of a larger corpus for their word list. The resulting corpus contains just over 1.75 million running words, which is relatively small. A danger with a small corpus is that lower frequency items might not have enough opportunity to occur, whereas high frequency items should occur frequently in any corpus. To develop a larger corpus would mean enlarging each of the subject areas overall. Any attempt to make specialised word lists from individual subject-specific corpora would require a much larger collection of texts in each subject area.
The written academic texts gathered for this corpus included study guides, laboratory manuals and textbook chapters from core texts. Academic staff members were consulted on the representative nature of the texts — that is, whether the texts were used in courses and were part of the expected reading of first-year students in those subjects. In several cases, online textbooks were included in the corpus, and they present a new challenge to corpus development. Publishers of online textbooks can update book chapters without waiting for a new edition which means that textbooks online are potentially more dynamic, so a chapter downloaded for a corpus might not be locatable in its same form online even in the space of a few short months.
The Science word list developed in this study by Coxhead and Hirsh (2007) contains 318 word families, which cover 3.71% of the Science corpus. The top ten items from this list are cell, species, acid, muscle, protein, molecule, nutrient, dense, laboratory and fluid. Once developed a word list can be used to explore the nature of specialised words in other contexts. Coxhead, Stevens and Tinkle (2010) used Coxhead and Hirsh Science list in a study of the vocabulary of secondary school Science texts and found that 264 word families from the Science list covered 5.9% of a series of four textbooks (279,733 running words). While the secondary school corpus is very small, this coverage figure suggests that these lexical items are useful for secondary school learners. The second 1,000 word families of West’s (1953) GSL also covers around 6%, but with nearly three times the word families. Therefore, those 264 word families are useful for secondary school students who are studying Science using those textbooks. However, there are clearly also differences in the kinds of Science vocabulary in secondary school and at university level, as can be seen in the coverage figures in the university study by Coxhead and Hirsh (2007) and the secondary study by Coxhead et al. (2010). Coxhead and Quero (2015) found that the Coxhead and Hirsh Science list covered roughly 6% of two corpora of Medical textbooks (both containing five million words). Another example of a Science word list developed from a corpus is reported in Greene and Coxhead (2015) based on Middle School textbooks in the USA (see Chapter 5 for more on these lists). A larger study is underway by Coxhead with a much larger corpus of secondary school Science texts. The focus of this study is to look more closely at the vocabulary of secondary school Science from a common core approach and to compare and contrast these existing word lists.