Vocabulary and English for Specific Purposes Research - Averil Coxhead 2018
High frequency/everyday words with technical meanings
The role and value of word list research for ESP
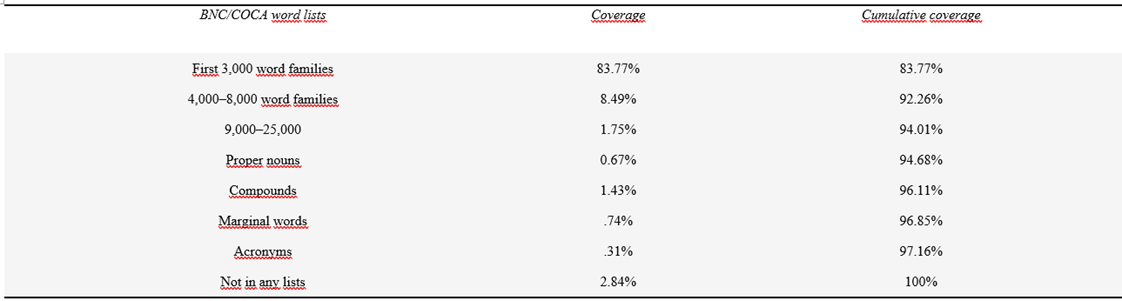
Table 3.4 Initial analysis of coverage of Nation’s BNC/COCA frequency lists over a Carpentry corpus
High frequency words can take on specialised meanings in particular contexts. The occurrence of high frequency or everyday words in ESP is not surprising, since these words carry a heavy load in any text in English. A feature of these everyday words is their sheer frequency, which means there is already an expectation of a reasonably high level of occurrence. But in specialised texts, these words may well also have a specialised meaning, and the closer they are to the topic of the text, the more frequently they will be used. Fraser (2009) refers to everyday words being used with a technical meaning as cryptotechnical because they have specialised meanings that might not be immediately obvious.
High frequency vocabulary is likely to represent a large percentage of words in a text, which means that high frequency words with technical meanings are likely to occur very frequently also. For example, Sutarsyah, Nation and Kennedy’s (1994) study found 34 words (including cost supply, and average occurred on average once every ten words in a university-level Economics textbook). One word in ten, in practical terms, is one occurrence per line of text. Their analysis showed that 20 of these 34 words were clearly essential to Economics. Contrast these everyday words in Economics with items such as sternum, costal, vertebrae in Anatomy from Chung and Nation (2003), which might stand out more in an ESP text because they look like medical words. Learners might have some expectations that highly specialised vocabulary looks different from everyday words, perhaps by being Graeco-Latin in origin or marked in terms of the narrowness of use. Specialised vocabulary, as Sutarsyah et al. showed in 1994, can include everyday words.
Another important reason for knowing more about the nature of everyday words and specialised meaning is that once an everyday meaning of a specialised word is known, it can be difficult to then apply that word to a new context. Teachers are aware of this problem. In an interview on specialised vocabulary, a secondary school teacher in Aotearoa/New Zealand commented that ’in Social Studies and History, students think they know words because they know the everyday meaning but they don’t know the specialised meaning [of the word]’ (Coxhead, unpublished data). Another secondary school teacher of Science in Aotearoa/NZ identified the other side of that problem when she said,
Teaching biology is like teaching a language subject. For every known word students are familiar with, there is a Biology word. For example, dissolve is not scientific English. It [Science] refers to solubility and insolubility. It relates to solute and solvent. Students have to be able to explain this meaning in a scientific context. If they use a scientific word in general terms, it will not be used in the correct way in normal language.
It is not only non-native speakers of English who might have this problem, as native speakers also face learning new meanings for words which are already known in an everyday sense.
Computer Science as a field of expertise is especially good at using everyday terms for specialised purposes (Radford, 2013). Words such as print, save, file, send and share all refer to common activities in word processing applications. At surface level, these words appear to mirror the everyday actions which preceded them involving pen and paper, such as file, save, open, close and folder but in Computer Science they have much more specific meanings. There are everyday words in Computer Science which are much less obvious, such as host (a computer) or string (a data type). Another example of a technical term in Computer Science is a software release train, which is a way to release versions of software for different projects using a planned schedule (Peter Coxhead, personal communication). A software release train is a form of software release schedule in which a number of distinct series of versioned software releases for multiple products are released as a number of different ’trains’ on a regular, pre-planned schedule. Users might work on several releases at a time while developers test, trial, release and polish aspects of software. This example also illustrates how multiword units can combine to form a new meaning.
It is not just in Computer Science that everyday vocabulary can be used with specialised meanings. Accurate and precise in Physics carry specific meanings which are not the same in everyday English (see Coxhead, 2012a). However, computer programmes such as RANGE (Heatley et al., 2002) tend not to differentiate between homographs. This means that items such as patient as a noun or adjective in Nursing or Medical studies are not flagged as being technical in nature. In such cases, researchers can use concordance programmes such as AntConc (go to www.laurenceanthony.net/software.html) to help decide how words such as patient are being used and in what patterns. Tom Cobb’s Compleat Lexical Tutor website (www.lextutor.ca/) allows users to create concordances of target items, either using corpora provided on the website or a corpus provided by the user. The context of any key word can be shown in one line or in an extended context, as shown in the comparison of the target word stress in Electrical Engineering and in spoken English in Figure 3.1.

Figure 3.1 Examples of the target word stress in an Electrical Engineering corpus and the BNC spoken corpus using Lex Tutor (Cobb, n.d.)
This process is an example of how quantitative corpus research can combine with qualitative methods. Developments in corpus linguistics research suggest that problems with homonyms (such as bank as in river bank and money bank to use examples from Cobb, 2013) can be addressed through corpus tools, for example by identifying, counting, and highlighting collocation patterns of the target words in context and allowing researchers to examine these patterns in concordances.