Vocabulary and English for Specific Purposes Research - Averil Coxhead 2018
Proper nouns as technical vocabulary
The role and value of word list research for ESP
Proper nouns are another example of everyday words which might have specialised meanings in particular fields. Proper nouns include names of places as in Wellington (the capital city of New Zealand), people (Peter Jackson, the film director), and other items such as companies (Toyota, Fonterra). Paul Nation’s proper noun list which is available as part of the RANGE BNC program (see Paul Nation’s website: www.victoria.ac.nz/lals/about/staff/paul-nation), is very useful for analysing the amount of proper nouns in a text or larger corpus. Proper nouns, such as Alzheimer as in Alzheimer’s Disease in Medicine and items which are part of a word string or phrase such as Maslow as in Maslow’s hierarchy of needs in Psychology, are also examples of everyday words which can also be identified as vocabulary for ESP. Proper nouns appear to have higher frequency in some disciplines, for example Medicine and History, than Mathematics (Greene & Coxhead, 2015). Proper nouns also occur in the trades, such as Aqualine, Braceline, Branz, Ecoply, Ezybrace, Flexibrace, Fyreline and Gantt in Carpentry (Coxhead et al., 2016). One debate about proper nouns is whether to include them in the first 1,000 words of English or to separate them from frequency analyses and a key caution is that proper nouns are not problem free for language learners (Brown, 2010; Nation & Kobeleva, 2016).
The number of proper nouns in texts can vary according to the subject area and specialisation of a text or corpus. A figure of around 2% seems to be regular in most general corpora. In the field of Education, the coverage figures of proper nouns in texts varies quite a lot. For example, Coxhead’s (2012c) study of secondary school English Literature texts found that proper nouns accounted for 1.92% of the words in the corpus of just over 88,000 running words. This figure is very close to Nation’s (2006) finding of just over 2% of the novel Lady Chatterley’s Lover. With specialised texts, however, the amount of proper nouns can be considerably higher. An initial analysis of a corpus of postgraduate Applied Linguistics research articles, textbook chapters, and other academic readings has proper nouns accounting for up to 4% (Coxhead, unpublished data). This figure is not surprising because the reference lists alone in such a corpus contain many names of authors and publishers. Proper nouns also account for over 4% of a corpus of Middle School textbooks in Social Sciences (see Greene & Coxhead, 2015), which is again not surprising considering the importance of place names and people in History and Geography. In the New Zealand context, we would expect to see proper nouns that reflect the people and the places in a History and Geography corpus that contains texts written about the country (for example, Māori, Wellington, Sir Edmund Hilary, the Treaty of Waitangi/Te Tiriti o Waitangi). However, we would also expect to see proper nouns that relate to people and places in other countries depending on the topics of the texts.
Medicine is another field where proper nouns can play a large role in a text. Two examples of proper nouns in Medical corpora from Quero (2015) illustrate difficulties they can present in corpus studies. These examples are Stevens-Johnson syndrome and Parkinson’s (disease). Stevens-Johnson and Parkinson could appear in a Medical text as an in-text reference for published papers, as a reference to the researchers in general, or as a reference to the syndrome or condition. An analysis of a 110,000 word corpus of Fabrication (welding) for polytechnic students found just under 1% of the text were proper nouns (Coxhead, unpublished data). Examples of high frequency proper nouns in a Plumbing corpus include Buchan, Eco, Kelvin, Legionella, Newton, Pascal, Pex, Swarf and Zincalume (Coxhead & Demecheleer, under review). More research on proper nouns in specialised subjects and professions is required, initially on identification of these items and how they are used in texts.
Table 3.5 The most frequent proper nouns in TED Talks six-by-six corpus (Coxhead & Walls, 2012)
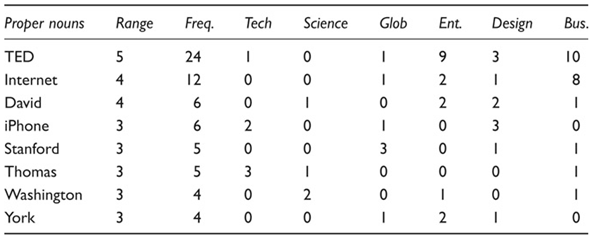
The range of proper nouns in a corpus is demonstrated in Table 3.5, which contains the nine most frequent proper nouns in a 43,000-word corpus of TED Talks (Coxhead & Walls, 2012). The corpus included six topic areas: Technology, Science, Global Issues, Entertainment, Design and Business. The purpose of the study was to investigate various word lists and their coverage over the corpus, to evaluate the vocabulary load of listening to TED Talks for EAP learners. Coxhead and Walls found that 629 proper nouns covered 1.44% of the total tokens in this corpus.
Note that in the table, TED is the most frequent proper noun, which is unsurprising given the nature of the corpus. The range figure in the second column indicates the occurrences of the proper nouns in the number of files out of the six in the corpus. The total number of occurrences in each file appears in the final six columns. TED occurs in five out of six of the files and that the occurrences are not balanced in each file (compare nine and ten occurrences in Entertainment and Business with the lower numbers in the other areas). The frequency of these proper nouns drops considerably from the most frequent to the least frequent.
In sum, the key points here about everyday words, abbreviations and proper nouns are that they can occur in different fields with specialised meanings, high frequency items with specialised meanings could possibly account for a fairly large amount of a text, and these specialised meanings may not necessarily be known by learners or even particularly easy to learn. Whether proper nouns and acronyms are considered to be part of a high frequency vocabulary or not is an important decision for word list developers (see Chapter 3). The examples of everyday words, proper nouns and acronyms have all been gleaned through corpus analyses, which is the focus of the next section.