Vocabulary and English for Specific Purposes Research - Averil Coxhead 2018
Quantitative approaches to identifying vocabulary for ESP - Corpus comparison
Approaches to identifying specialised vocabulary for ESP
Corpora are commonly used in quantitative studies for identifying vocabulary for ESP in corpus-based research. A corpus is a body of texts of written or spoken language, and, increasingly, a corpus can be multi-media. An early example of multi-media in EAP is Hilary Nesi’s Essential Academic Skills in English (EASE) series (see Nesi, 2001). Corpus-based studies allow for larger-scale investigations of words in context than early studies of page-by-page analysis by hand. A key feature of corpus analysis is that such studies should be relatively easy to replicate, but only if the corpora are publicly available. Unfortunately, many corpora are not made available for further analysis, but some corpora have been made publicly available, such as the British Academic Written English Corpus (BAWE) and the British Academic Spoken English Corpus (BASE) (both available at sketchengine.co.uk) and the Hong Kong Polytechnic University Corpora of Professional English (available at the website for the Research Centre for Professional Communication in English: rcpce.engl.polyu.edu.hk).
In specialised vocabulary research, a corpus of a particular field could contain a range of texts. For example, in Nelson’s (n.d.) work on business-specific vocabulary, four corpora were used: the written texts of business people, texts which they read, their spoken texts and texts which they listened to. This organisation of the corpus illustrates Nelson’s concern that a corpus represents, as much as possible, the kinds of documents or texts of that field. Corpus studies have contributed a great deal to our quest to identify and understand more about specialised vocabulary. They have been particularly useful for developing word lists for use in language classrooms and for independent study. Cheng’s (2012) volume on corpus linguistics contains clear step-by-step instructions on extracting lexis from a corpus, for example, to generate a word list and research single words, as well as ways to identify multi-word units in corpora through n-gram analysis (see Cheng, 2012, for example).
The following are some ways that researchers have investigated corpora to identify specialised vocabulary in ESP.
Corpus comparison
A fairly quick way of finding technical vocabulary is using a corpus-comparison approach which involves, obviously, two corpora. One is a specialised corpus and the other is a general-purpose corpus. First of all, items which only occur in the technical or specialised corpus are labelled ’technical’ whereas those in the general corpus are labelled ’not technical’. For any comparison like this, there will be clear examples of lexical items which will occur only in the specialised corpus and not in the general corpus. For example, comparing a Carpentry corpus with a fiction corpus, words such as insulation and cladding only occur in the Carpentry corpus (Coxhead, Demecheleer, & McLaughlin, 2016). The second step is to look at shared items between both corpora. Each word is compared using a ratio depending on its frequency in either corpus. For example, Chung (2003) decided on a ratio of 50 occurrences in the specialised corpus to one occurrence in the general corpus and found that with this ratio, lexical items that were 50 times more frequent in the specialised corpus had more than a 90% chance of being technical vocabulary. Chung and Nation (2003) compared the corpus-comparison approach with several other methods of identifying technical vocabulary, including technical dictionaries and using a scale (see the following). They found corpus comparison to be the most practical and effective method option for identifying technical vocabulary.
Gardner and Davies (2014) used corpus comparison for their Academic Vocabulary List (AVL), based on the 120-million-word academic subsection of the Corpus of Contemporary American English (COCA) corpus. This subsection of the corpus contains journal articles, newspapers and magazines, with journal articles constituting around two thirds of the sub-corpus. The sub-corpus is divided into 11 disciplines: Business and Finance, Education, Humanities, History, Law and Political Science, Medicine and Health, Philosophy, Religion, Psychology, Science and Technology and Social Science. The smallest section contains 8,030,324 running words and the largest contains 22,777,656 running words. The AVL is explored in more detail in Chapter 3.
Table 2.1 Quero’s (2015) top ten medical words in a Medical and a general English corpus
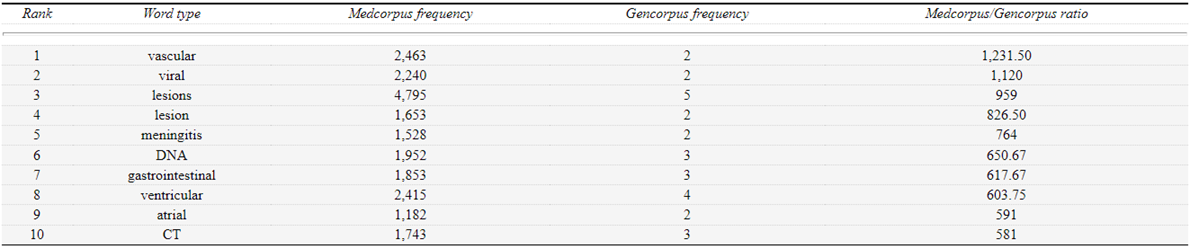
Table 2.1 shows the ten most frequent items and their relative frequencies from a comparative analysis of a Medical textbook corpus and a general English corpus from Quero’s (2015) study of Medical vocabulary in textbooks for university study. Note how much more specialised and frequently occurring words such as vascular and viral are in the Medical corpus relative to the general corpus.
Abbreviations such as DNA are included in the table because these lexical items are particularly prevalent in Medical texts.