Vocabulary and English for Specific Purposes Research - Averil Coxhead 2018
Pre-university studies: vocabulary in English for general academic purposes
Pre-university, undergraduate and postgraduate vocabulary
Studying at university can mean exposure to several million running words a year through reading textbooks, source books, content and learning-based websites and other academic sources of information. Pre-reading for lectures, tutorials and laboratories is commonly assigned to learners. The nature of the words encountered while reading academic texts is a fundamental area of research into university language. An example of this research is work carried out by Miller (2011) whose US-based study analysed the percentage of the AWL (Coxhead, 2000) as well as readability/complexity and syntactic features of the texts in two corpora: university textbooks and ESL reading books. The textbook corpus contained six disciplines: Business, Humanities, Natural Science, Social Science, Education and Engineering. In the AWL comparison, Miller found that roughly half the number of AWL items were in the ESL reading materials as were in the university-level texts. Miller (2011) points out that this figure means that on an average page of 400 words, an ESL textbook would contain approximately 15 fewer AWL items per page than a university textbook. Miller (2011) comments,
It is possible, then, that the ESL textbooks are providing students neither the exposure to the range of academic vocabulary nor the number of encounters with academic vocabulary that they may need to develop successful comprehension of university textbooks.
(Miller, 2011, p. 39)
Written academic texts have been gathered into corpora for analysis of lexis which is shared across disciplines. Examples of this kind of research include, for example, Coxhead’s AWL (2000), Gardner and Davies (2014), Browne, Culligan and Phillips (2013a) and Liu (2012).
Academic word lists have started from two different points, as we have already seen in Chapter 2. One way is to assume that EAP learners have a basic general knowledge of vocabulary before they start to specialise in academic studies. Coxhead’s AWL is an example of this approach, drawing on the most fully formed and principled general word list available in the late 1990s, West’s (1953) GSL. The coverage of the AWL has been reported in a range of studies since the original 2000 study by Coxhead (see Table 6.1). Note that the studies with higher coverage of the AWL tend to be on written academic texts, while spoken academic texts and secondary school texts have lower coverage figures, overall.
Table 6.1 Coverage of the AWL over a range of academic corpora by frequency (adapted from Coxhead, 2011c, p. 356)
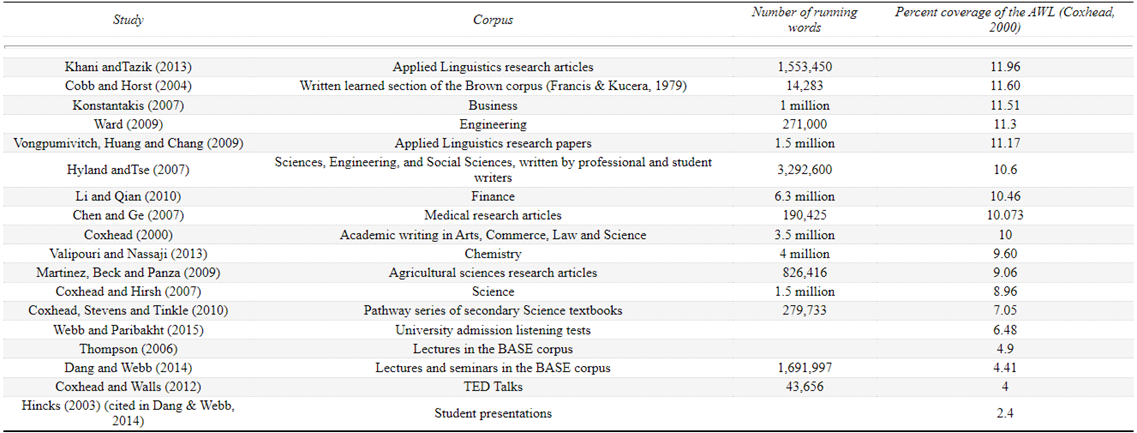
As well as researching the coverage of the AWL over spoken academic texts, Dang and Webb (2014) used the BASE to find out more about the vocabulary profile of these texts. The 1,691,997-word corpus contained four discipline areas: Arts and Humanities, Life and Medical Sciences, Physical Sciences and Social Sciences. Dang and Webb (2014) found that 4,000 word families plus proper nouns and marginal words provided 96.05% coverage of the corpus, and 8,000 word families provided 98% coverage. Life and Medical Sciences, however, took 13,000 word families plus proper nouns and marginal words to reach 98.05% coverage families. Again, studying in the Sciences seems to involve a larger vocabulary load than other academic disciplines.
The AWL has also been investigated in a range of studies that focus on textbooks for university students and EAP learners. Miller (2011) carried out a lexical analysis of 75 reading texts from 3 EAP student textbooks and 28 university textbooks from 6 academic disciplines. This study found that EAP textbooks contained fewer items from the AWL than the university textbooks.
Another example of an academic word list which takes high frequency general English into account is Browne et al.’s (2013a) New Academic Word List (available at www.newgeneralservicelist.org/nawl-new-academic-word-list/). This list was developed from a corpus of over 288 million running words. The corpus was in three main sections: the Cambridge English Corpus of academic journals, non-fiction, student essays and academic discourse (over 248 million words); the Michigan Corpus of Academic Spoken (MICASE) and BASE corpora (three million words); and an academic textbook corpus (approximately 36 million words). Browne et al. (2013b) excluded the vocabulary in their New GSL, developed from the two-billion-word Cambridge English Corpus (and available at www.newgeneralservicelist.org/). The resulting word list contains 963 words, such as repertoire, obtain, distribution, parameter, aspect, dynamic, impact, domain, publish and denote. The list is available in several formats: headwords, lemmas, a bilingual English and Japanese list of meanings of the words in the list and a frequency-based version of the list.
There are several weaknesses of an approach that assumes learners already have knowledge of high frequency words when building an academic word list. One is whether learners actually do know a basic vocabulary before they start learning vocabulary for EAP. Studies in Vietnam (Webb & Chang, 2012; Nguyen & Nation, 2011), Denmark (Henriksen & Danelund, 2015) and Indonesia (Nurweni & Read, 1999) suggest that foreign language learners tend not to show mastery of the first 1,000 words of English even after quite a few years of studying the language. Such estimates in English as a second language contexts are not so readily available. There are now more general word lists, including Nation’s (2006) BNC lists, a later BNC/COCA high frequency word list also by Nation (2012), Brezina and Gablasova’s (2015) New GSL, and Browne et al. (2013b) list, which is also called a New GSL List. Dang and Webb (2014) compared the first four of those existing general word lists over a large corpus of spoken and written general English texts in their quest to develop a word list for beginners. They broke their Essential Word List into sets of 100 items and argued for an overall size of 800 items in the list because the number of items sets a reasonable and focused goal of high frequency words for learners and teachers.
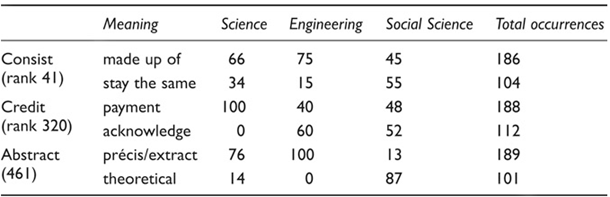
Hyland and Tse (2007) were critical of Coxhead’s (2000) approach of identifying vocabulary occurring across a range of academic subjects, pointing out that lexis can behave differently in terms of meaning and grammatical patterning in texts. Hyland and Tse (2007) compared lexical items in Coxhead’s AWL in professional and student writing corpora in Science, Engineering and Social Science. They found variations in frequency and in meaning in these corpora. Table 6.2 shows examples from Hyland and Tse (2007) of consist, credit, and abstract from the AWL. The meanings of these words are in the second column, with the number of occurrences of the words in Science, Engineering and Social Science in the next columns. Note the meanings are presented in the order of the highest total occur-rences overall.
Table 6.2 Examples (adapted from Hyland &Tse, 2007, p. 245) of the distribution of meanings of consist, credit and abstract across three disciplines (%)
Gardner and Davies (2014) developed their AVL by starting from scratch, that is, without any assumption of high frequency vocabulary. Gardner and Davies (2014) used a ratio-based corpus-comparison approach, based on a 120-million-word academic section of the COCA. The academic corpus contained 13,000 academic journal articles and magazine articles with an academic orientation in the following nine subject areas: Business and Finance, Education, History, Humanities, Law and Political Science, Medicine and Health, Philosophy, Religion and Psychology, Science and Technology and Social Science. The AVL is available in three formats: a word family list of 1991 words, a list of 3,015 lemmas and a list of 20,845 word types. The AVL coverage over the academic COCA and the academic sections of the BNC is 14% (Gardner & Davies, 2014). This coverage is higher than Coxhead’s AWL coverage over her academic written corpora (10%) and most academic written corpus-based studies of the AWL (see the aforementioned). This difference in coverage comes from general high frequency words such as so and because meeting the selection criteria for the word list.