Vocabulary and English for Specific Purposes Research - Averil Coxhead 2018
Using word lists for research into vocabulary in ESP - Analysing and comparing the vocabulary load of texts
The role and value of word list research for ESP
In this section, I explore how research that has resulted in word lists is used in other vocabulary research to find out more about the nature of vocabulary in ESP.
Analysing and comparing the vocabulary load of texts
Word lists have also been used to research the vocabulary coverage of texts and find out more about the nature of the lexis in written and spoken texts. Coxhead et al. (2010) investigated the extent to which existing word lists (AWL and the Science List from Coxhead & Hirsh, 2007) could be a shortcut for learners reading secondary school texts. Table 3.8 shows the running totals of coverage over four secondary school Science textbooks in a series, from the first year of secondary school (Year 9) through to Year 12. Coxhead and Hirsh’s (2007) Science word list covered 3.18% of their university-level corpus, whereas the list covered 5.8% of the secondary school Science textbooks on average. This higher coverage by the list suggests that the secondary school texts contain more high frequency words than do university-level texts. Similarly, the AWL coverage over the secondary school Science texts (5.8%, on average) is lower than the coverage over Coxhead’s (2000) university-level Science sub-corpus from her written academic corpus (9%). This finding suggests that university-level texts use more AWL words than secondary school texts (see Chapter 5 for more on specialised vocabulary in secondary school contexts).
Table 3.8 Coverage of the GSL/AWL/Science-specific lists over the four secondary Science textbooks (adapted from Coxhead et al., 2010, p. 46)
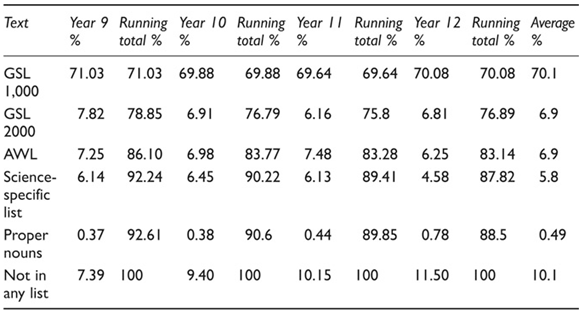
The coverage of the second 1,000 words from West’s GSL (1953) is worth mentioning because this list covers 2% more over these Science textbooks than over other kinds of texts. This higher coverage can be explained by the high number of occurrences in the text of items such as ray, electric, reflect, angle and temperature (Coxhead et al., 2010). Note the increase in proper nouns and words not found in any list from the Year 9 text through to the Year 12 text. Coxhead et al. (2010) concluded that these existing word lists do not go far enough to cover the vocabulary needed by second language learners working with these textbooks in schools.
A recent study of Computer Science journal articles by Radford (2013) used Nation’s BNC lists to investigate the vocabulary load of those texts over the decades from the 1950s to the 2000s. Radford also gathered first-year university teaching materials for a second corpus and textbooks for a third. His findings make sobering reading for teachers and researchers of Computer Sciences. Firstly, the vocabulary load of journal articles was far higher than the textbooks and teacher-generated material (for more on these results, see the following). The teacher materials had the lowest vocabulary demands, which suggests that the teachers had mediated the vocabulary load of the reading they were giving to the students. These results fit with other studies which look at the vocabulary load of university-level texts, such as Nation (2006). The next most difficult texts from a vocabulary perspective were the Computer Science textbooks. Finally, the journal articles had a much larger vocabulary load. Radford’s (2013) results showed the cumulative coverage of the corpus dropped from 79% (approx.) coverage at 30,000 + proper nouns in the 1950s journal articles section of his Computer Science corpus to 65% (approx.) at 30,000 + proper nouns in the 2000s section of this corpus. This study rather starkly demonstrates the kind of specialised vocabulary that could be needed to read Computer Science journal articles and suggests that more such work needs to be done in vocabulary research.
A closely related issue in research on the size of a technical vocabulary is how that vocabulary changes over time. Radford’s (2013) study suggests that vocabulary in Computer Science has changed and grown rapidly in just half a century. More such studies could be carried out to track changes in specialised vocabulary over time and inform our understanding of the kinds and rates of change in a variety of areas.