Vocabulary and English for Specific Purposes Research - Averil Coxhead 2018
Specialised vocabulary for legal purposes
Specialised vocabulary research and the professions
Vocabulary in Legal English has a reputation for being particularly difficult and recent growth in international law has increased the need for learning this lexis (Breeze, 2015). Breeze comments that there is a need for more research into Legal vocabulary and the way it functions in Legal texts. Maher (2016) used a keyword analysis of a corpus of one million running words of postgraduate legal student writing (essays and theses) with the BAWE corpus to develop a list of semi-technical Legal vocabulary which was shared between a range of Legal disciplines. As well as uncovering a range of Legal vocabulary, such as court, law, justice and article, Maher (2016) noted preferences in the Legal English writing for particular verbs (e.g. hold, state, note and require). Maher’s (2016) analysis also focused on high frequency words in the data set (that and of) and their functions in the corpus, such as referring to sources and evaluation by the writer.
As well as there being a variety in specialised vocabulary in areas of law and Legal texts, Northcott (2013) notes that a key point in English for Legal Purposes is that different legal systems mean that different language might be required. This means that research into this area of vocabulary needs to be careful in selecting any texts for a corpus analysis in Law for a particular group of learners or purposes. For example, Marín (2014) focuses on vocabulary from the United Kingdom Supreme Court in her quest to identify Legal vocabulary to support law students in the Spanish context, while Hartig and Lu (2014) focus on plain English and Legal writing in law schools in the United States by novice and professional writers.
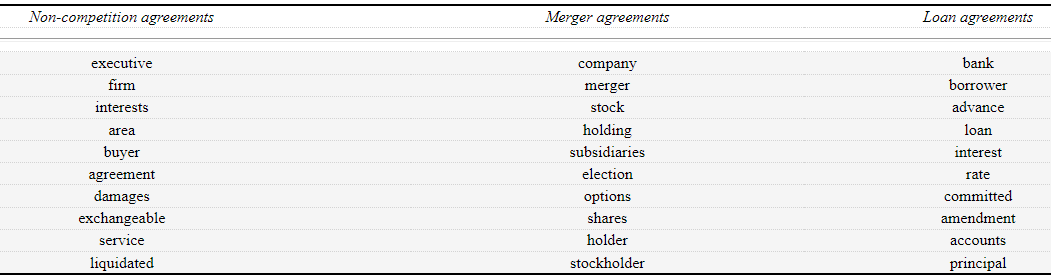
To identify Legal vocabulary, Breeze (2015) developed a 400,000-word corpus of legal documents downloaded from the Internet. These documents included ten legal text types, for example, contracts of sale, non-competition agreements, merger agreements and lease agreements. A frequency count helped identify the most frequent words in the corpus and a comparison with the BNC frequency lists cited in Scott and Tribble (2006) indicates that there are major differences between general and Legal English vocabulary. For example, shall, company and agreement occur in the first 20 words of the Legal frequency list and board, obligations and forth occur in the first 100 words. Breeze (2015, p. 50) also investigated Legal collocations and clusters in her corpus. High frequency items included subject to, in effect, shall have the meaning set forth, and any interest in. The ten areas of the corpus were all investigated for specialised vocabulary, rather than general Legal vocabulary. Table 7.1 contains examples of keywords from Breeze’s analysis. These keywords were identified through comparing the subcorpora with the whole corpus. The keyness factor for these words is 45.
Table 7.1 Examples of specialised vocabulary from Breeze (201 5, p. 58)
In a practical study of the technical vocabulary of law, Csomay and Petrović (2012) identified instances of Legal terminology in a 128,897 word corpus made up of transcripts from legal television shows (e.g. Law and Order) and movies (for example, A Few Good Men and Runaway Jury and checked the words in legal dictionaries. They identified technical words, such as bar, constitute, deny, court, document and excuse, covered more than 5% of their TV and movie corpus. Csomay and Petrović (2012) found that technical vocabulary was not evenly distributed throughout the movies and television programmes. It makes sense that courtroom scenes may well contain more legal lexis than other scenes in such shows. The amount of technical word families per movie (22.4) differed from the amount per TV episode (12.2). Examples of high frequency specialised Legal vocabulary in the corpus, such as argue (for example, I’m prepared to argue the motion) and depose/deposition (I’m going to depose Mr Lefkin. The deposition is set for next Thursday afternoon. I’m going to take depositions from all the executives), illustrate how these legal terms are used (Csomay & Petrović, 2012, p. 312) in context. This study is particularly interesting because it interrogates a spoken corpus as a resource for encountering specialised vocabulary in context and illustrates how the research can be used for pedagogical purposes. Attempts to help law students with vocabulary in Legal writing include Hafner and Candlin’s (2007) study in Hong Kong, using a set of online tutorials, a concordancer and a collocation tool. The study found on the whole that rather than using these tools for lexical support, the students were more likely to be searching for examples of legal documents (for example, affirmation or defence and counterclaim) that they were required to write for their course (Hafner & Candlin, 2007, p. 312). The students were patchy in their use of the corpus tools as lexical support. That said, there was recognition by the students of a specialised Legal corpus as being a useful source of language.